Data is key to making informed decisions for businesses. It helps businesses answer some of the most burning questions about their customers, how much it costs to acquire a new customer, or how to improve their products or services. Furthermore, the amount of data produced today is growing exponentially. In fact, 90% of the data existing today has been created over the last two years.
As businesses rely more on their data at their fingertips, data engineering is becoming quite prominent. In this article we will review data engineering best practices worth considering today. But let’s start from the top.
What is data engineering and some of its main components
Data engineering is the process of making sense of large amounts of data. It collects raw data from various sources and transforms it to make it accessible and usable to data scientists and other end users within the organization.

Without this structuring, companies’ large amounts of data are useless as they can’t be used to drive conclusions or affect decisions. Data engineering concepts provide valuable insights into available data that can substantially impact a company’s growth, predict future trends, or understand network interactions.
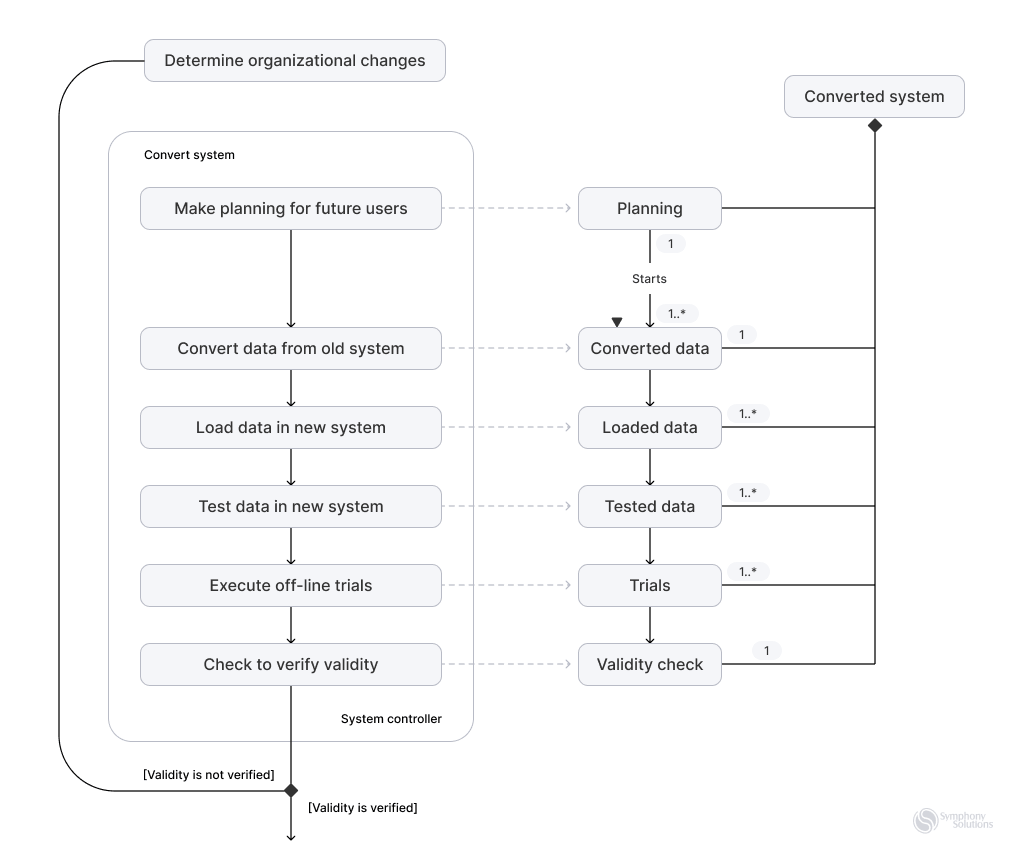
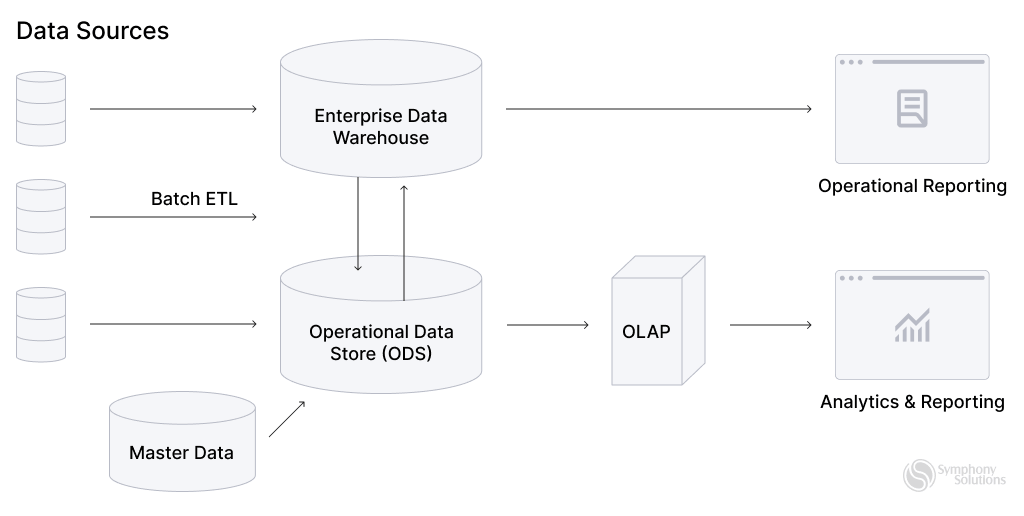
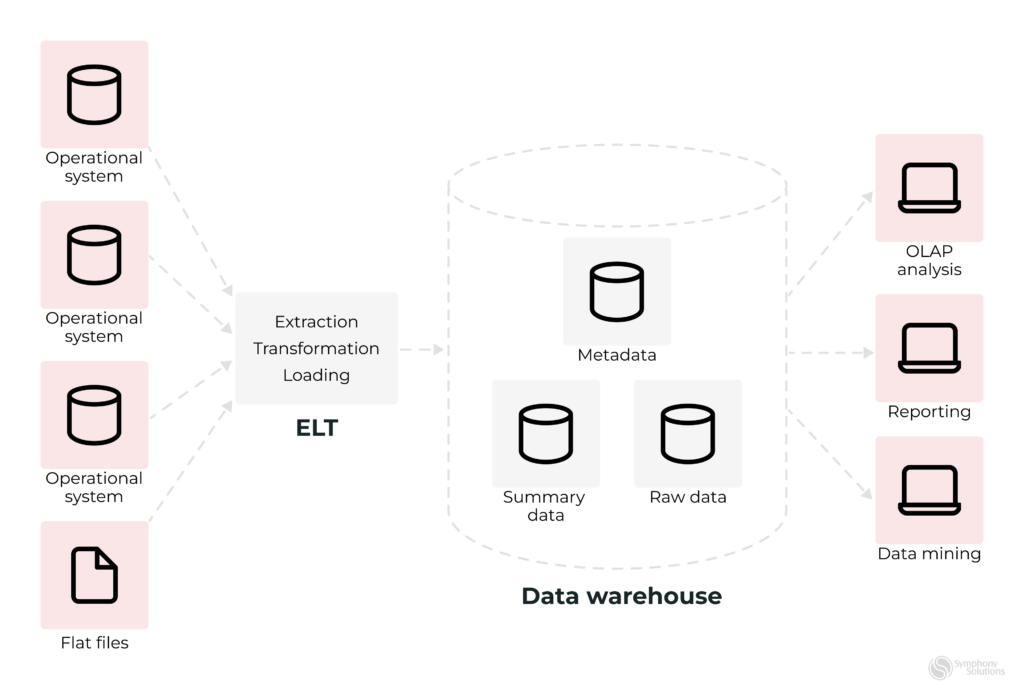
Additionally, data engineering considers the end-to-end process as data pipelines that transform and transport data to present it in a form that can be analyzed and used to drive some insights. The pipelines take data from one or various sources and collect them in a single warehouse to consolidate one single source of truth.

The common elements of the data pipeline are:
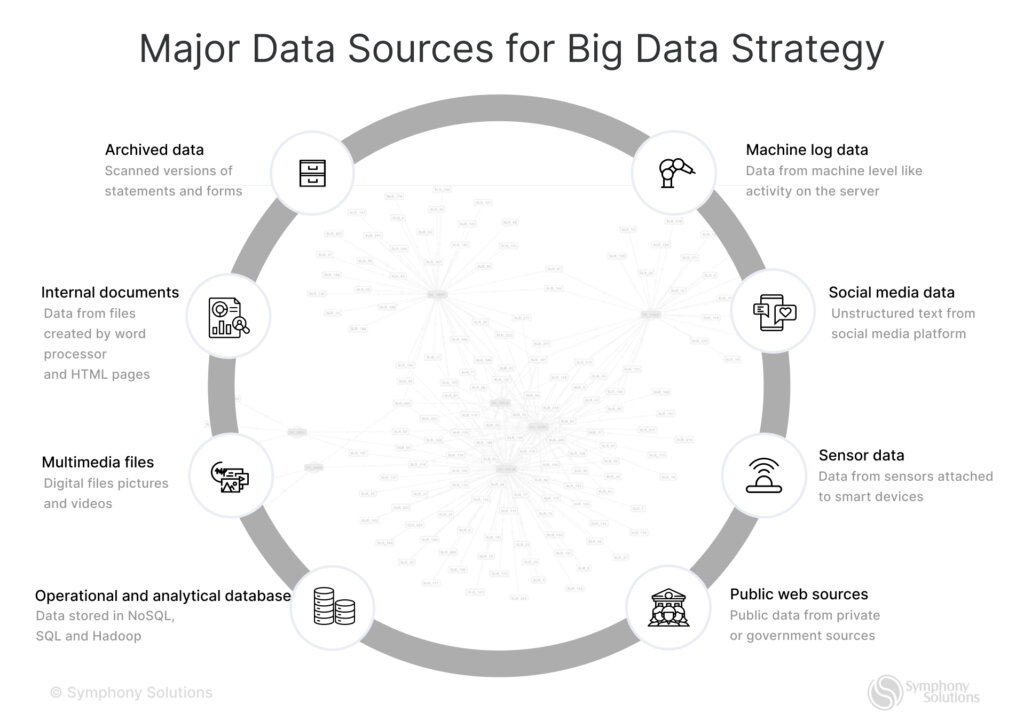
- Source(s) – one or various sources that data comes from, such as database management systems (e.g., MySQL), CRMs (e.g., Salesforce, HubSpot), ERPs, some SM management tools, or even IoT devices.
- Processing steps involve extracting data from the sources, transforming and manipulating it according to business needs, and then depositing it at its destination.
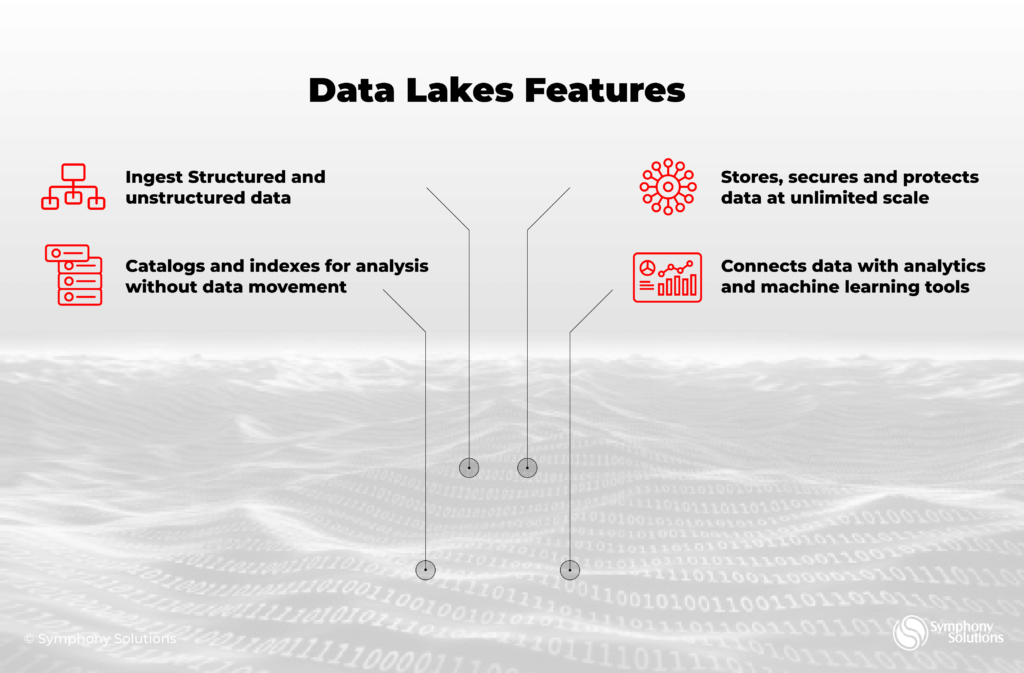
- Destination – is typically a data warehouse or data lake, a place where data arrives after being processed.
Building a data-first company starts with organizing your data and its various sources. Data engineers here play a strategic role, having the capability to harness the full potential of data and how it affects the entire organization. When it comes to making the most of your data, there are some best practices in data engineering to follow:

24 best practices in data engineering
Data engineering involves creating and managing systems for collecting, storing, and analyzing large volumes of data. Here are the best practices to ensure data is accessible, reliable, and ready for analysis:
Make use of functional programming
Functional programming is a perfect choice when working with data. ETL (Extract, Transform, Load) is challenging, often time-consuming, and hard to operate, advance, and troubleshoot. Applying a functional programming paradigm brings a lot of clarity to the process, which is essential for large volumes of data. Additionally, it enables the creation of code that can be reused across multiple data engineering tasks.
Practice modularity
Building a data processing flow in small, modular steps is another best practice in data quality and quality engineering. Modularity means that each process step is focused on a specific problem, making code easier to read, reuse, and test. Modules can also be easily adapted independently, which is especially useful as the project grows. Modules built with a set of inputs and outputs suitable for numerous contexts will make data pipelines clean and easy to understand from the outside, and thus, they can be easily reused in the future.
Follow proper naming convention and proper documentation
Proper naming conventions and documentation are sound data engineering principles that can help a team be on the same page and collaborate more effectively. This is especially useful when the owner cannot make changes or modifications. Make it a rule inside the team to provide proper explanatory descriptions of pipelines, jobs, components, and use cases it might solve.
When it comes to naming, strive to name the objects in a way that makes it clear to a new person who might join the team and avoid confusing abbreviations. As for creating useful documentation, it should focus on explaining the intent behind what the code is doing rather than stating the obvious.
Select the right tool for data wrangling
With the large amounts of data and data sources that keep growing, it’s extremely important to keep the data clean and organized for easy access and analysis. A data wrangling tool can tackle any inconsistencies in data and transform distinct entities, for instance, fields, rows, or data values within a data set, making them easier to use. The clean is the data you feed, the data and more accurate insights you can expect. Data wrangling tools can help detect, drop and correct records prepared for the data engineering pipeline.
Strive for easy-to-maintain code
Being clear and concise are the principles that also apply when writing code. Making it readable and easy to follow is a good practice that will help everyone on the team to work with it in the future. Some of the best code development principles to follow here are:
- DRY (Don’t repeat yourself) aims to reduce the repetition of software patterns and code duplication by replacing them with abstractions to avoid redundancy.
- KISS (keep it simple, stupid) strives to keep the code clean and understandable. The principle suggests keeping the methods small, never more than 40-50 lines. Each method should only solve one problem. A method with many conditions should be broken down into smaller methods. Thus, it will be easier to read, maintain, and potentially debug faster.
Use common data design patterns
Data design patterns are repeatable solutions to common, occurring problems in software design. They provide a problem-solving template that could be used as a basis for designing a solution. Creating data design patterns provides techniques, tools, and processes that could speed up the development process. Patterns can help keep track of the existing types and counts of data pipelines and simplify communication between developers by using well-known and understood names.
Build scalable data pipeline architecture
Useful insights and analytics rely on efficient data pipelines. The ability to scale as data sources increase is detrimental here. That’s why building pipelines that can be easily modified and scaled is a good practice. This practice is called DevOps for data or “DataOps” and focuses on delivering value faster by using automation and sometimes AI to build continuous integration, delivery, and deployment in the data pipeline. Embracing DataOps will improve the usability and value of data and make it more reliable and accessible.
Ensure the reliability of your data pipeline
Ensure monitoring and alerting are built-in to get notified when your data pipeline fails. Focusing on the reliability of your data engineering pipeline by regularly checking error notifications ensures consistency and proactive security. This way, the quality of data can be easily identified and monitored.
Follow some general coding principles
Some general best coding practices can also be applied to data engineering, such as avoiding hard or dead code. To utilize the code base in different environments in the future, avoid hard coding values. Instead, make your pipelines configurable. Another good practice is avoiding keeping someone’s abandoned code. Removing it will help keep the code base clean and easy to understand for other developers in the future.
Set security policy for data
To prevent any potential security or regulatory issues, data owners or producers need to recognize and set data sensitivity and accessibility. How the data is used, who uses it, and where it’s shared should be clear. Some steps for setting the security policy for your data include classifying data sensitivity, developing a data usage policy, monitoring access to sensitive data, physical security of data, using endpoint security systems for protection, policy documentation, employee training, and multi-factor authentication.
Optimize Cloud Costs
Regularly review and optimize cloud resource usage to control costs and ensure you’re not overspending on unused or underutilized resources. This involves using cost-management tools provided by cloud platforms to monitor usage patterns and identify areas for savings. Additionally, implementing policies for efficient resource allocation and deallocation can help prevent unnecessary expenditures.
Implement Version Control
Use version control systems like Git to manage changes in your data engineering projects, ensuring you can track changes and collaborate effectively. Version control allows multiple team members to work on the same project without overwriting each other’s work. It also provides a history of changes, which is invaluable for debugging and understanding the evolution of the project.
Manage Incidents Efficiently
A robust incident management process is essential for quickly identifying, responding to, and resolving issues in your data pipelines. This includes setting up monitoring and alerting systems to detect failures and anomalies. A well-defined incident management plan ensures that issues are documented, prioritized, and resolved efficiently to minimize downtime and maintain data integrity.
Automate Data Pipelines and Monitoring
Implement automation for data pipelines and monitoring to improve efficiency and reduce the risk of human error. Automation tools can handle repetitive tasks, ensure data quality, and provide real-time monitoring. By automating these processes, you can achieve faster deployment times, consistent performance, and more reliable data management.
Focus on Business Value
Ensure that your data engineering efforts are aligned with business objectives to deliver maximum value to the organization. This involves understanding the business’s key metrics and goals and designing data solutions that provide actionable insights. Data engineers can help drive strategic decision-making and improve overall business performance by focusing on business value.
Avoid Data Duplicates with Idempotent Pipelines
Design your pipelines to be idempotent to prevent data duplication and ensure consistent results. An idempotent operation produces the same result even if executed multiple times. This approach helps maintain data integrity and simplifies error handling, making it easier to recover from failures without introducing duplicate data.
Track Pipeline Metadata for Easier Debugging
Keep detailed metadata about pipeline runs to make debugging and tracking easier. Metadata should include information about the timing, method, and data content processed in each run. This transparency helps identify issues quickly and provides a clear audit trail, essential for troubleshooting and compliance.
Use Airflow for Workflow Management
Apache Airflow is a powerful tool for orchestrating complex data workflows. It allows you to define, schedule, and monitor data pipelines through a user-friendly interface. Airflow helps manage dependencies, track progress, and handle failures effectively, ensuring smooth data pipeline operations.
Ensure Data Quality
Implement data quality checks to ensure that data is valid before it is exposed to end-users. High-quality data is crucial for reliable insights and decision-making. Use tools and processes to validate, cleanse, and monitor data quality continuously.
Implement Thorough Testing
Regular testing of data pipelines is essential to ensure they function as expected. Implement unit tests, integration tests, and performance tests to validate data transformation logic, check for errors, and ensure pipelines can handle expected loads.
Optimize Heavy Computational Tasks
Pay attention to where the heavy lifting occurs in your data pipeline. Ensure that computationally intensive tasks are optimized and placed appropriately, either in the cloud or on-premise, to balance cost and performance effectively.
Embrace DataOps
DataOps focuses on improving collaboration, integration, and automation of data workflows. By adopting DataOps practices, you can enhance the efficiency, reliability, and scalability of your data engineering processes, leading to better data management and faster delivery of insights.
Use Standard Data Transformation Patterns
Apply standard patterns for data transformation to ensure consistency and efficiency. These patterns help maintain a clear structure and logic in your data pipelines, making them easier to understand, maintain, and scale.
Leverage AI in Data Engineering
Artificial Intelligence (AI) can significantly enhance data engineering by automating data processing tasks, optimizing data pipelines, and providing advanced analytics. Incorporate AI tools and techniques to improve efficiency, accuracy, and scalability in your data workflows.
The Future of Data Engineering: AI, IoT, and Cloud Computing
The future of data engineering is being reshaped by Artificial Intelligence (AI), the Internet of Things (IoT), and Cloud Computing, promising significant advancements in efficiency and innovation.
Artificial Intelligence (AI) is set to automate and enhance data analysis, enabling faster and more accurate insights from vast datasets. It will play a crucial role in real-time analytics and predictive modeling, streamlining the data engineering process.
Internet of Things (IoT) integration is providing a constant stream of real-time data from connected devices. This surge in data will necessitate advanced data engineering techniques to manage and derive value from diverse information sources.
Cloud Computing offers scalable and efficient data storage and processing solutions. It’s evolving to integrate AI and machine learning, simplifying data engineering tasks and enabling sophisticated data analysis.
In essence, the combination of these technologies will transform data engineering, enabling businesses to handle complex data more efficiently and drive data-centric decision-making.
The Takeaway
Data engineering, significantly impacted by technologies such as cloud computing, IoT, and artificial intelligence, is evolving at an unprecedented speed. The decisions you make regarding your data pipeline can drastically influence your business’s profitability, growth, and potential for losses. Adhering to data engineering best practices is essential to avoid increased expenses and time spent on unnecessary tasks. If you are interested in building a reliable data pipeline that aligns with your business goals, our expert data engineers are here to assist you. Don’t hesitate to contact us with any questions you might have, or to get started on developing a data pipeline tailored to your needs.
Ready to transform your data management strategy? Visit our Data Analytics Services Page now to learn more about our solutions and take the first step towards efficient and impactful data engineering.